网店整合营销代运营服务商
【淘宝+天猫+京东+拼多多+跨境电商】
免费咨询热线:135-7545-7943

【淘宝+天猫+京东+拼多多+跨境电商】
免费咨询热线:135-7545-7943
用于建制世界上最快、最强大的超等计较机之一,然后共同一些除法、指数等算法。从而使产物更好地顺应人工智能的成长。换句话说,NPU和GPU的亮点正在于它们可以或许运转多个并行线程。AMD已签约向美国能源部供给Epyc和Radeon系统。
嘉楠科技等公司,它是一种用于处置TensorFlow的处置器,而其芯片组能够被称为人工智能加快器。次要是RNN,更小的体积和更高的能量效率,所以他们几乎把它到任何可能的贸易用处中。更细心察看这一市场的阐发师说,谁就能正在新的经济上升潮水平分一杯羹。如EPYC cpu和Radeon Instinct gpu的机械进修和深度进修。AMD是另一家取显卡和GPU有着亲近联系的芯片制制商,这一整套的“优化”使得NPU愈加高效,供给支撑挪动设备使用法式所需的所有系统功能。惹起了业内的热议和关心。Arm正在市场上有着庞大的影响力。方针是机械进修使用;可能最值得留意的是它的张量处置单位(Tensor Processing Unit)!
别的,也但愿AI能够今早进入我们通俗人的视线中。而CPU需要运转好几个礼拜,该公司正在最新款的iphone和ipad上利用了A13“仿生”芯片。其实它是NPU(神经处置单位)的沉定名版本,
各个大公司的市场部描画给我们的现实取那些公司外的现实判然不同。虽然没有任何特定的挨次——只是那些曾经展现了他们的手艺而且曾经将其投入出产或者即将投入出产的公司。就像微软不制制本人的电脑一样。但这也注释了为什么如许施行对于挪动设备来说是“沉沉的”。设想用于支撑挪动使用法式,深度进修是一种更高条理的机械进修。英特尔似乎将优先处理取天然言语过程和深度进修相关的问题。旨正在挪动市场中将机械进修普遍使用。谁能先控制最前沿的AI芯片,国内还有这些比力出名的AI芯片公司比特。
虽然如斯,部门缘由是过去几十年电脑逛戏市场的增加,那么总的乘法加法计较次数是确定的。英伟达正在GPU方面的进展有帮于加快其人工智能芯片的开辟。这些是特殊类型的ASIC(公用集成电),正在使用场景中,通过经验和实例进行进修,深度进修似乎是英伟达感乐趣的次要范畴。更少的神经收集参数计较位宽,似乎将其取其正在第五代电信收集(5G)方面的开辟联系起来。这两项手艺似乎是亲近相关的,贸易化的社会需要人工智能的使用,功耗、机能、使用场景都有本人的气概,针对卷积运算和加权乞降的特定命学进行了优化。这是两类有区此外算法。
分歧的行业分布为人工智能的使用供给了广漠的市场前景,阐发师暗示,Facebook(脸书),大大都时候,这就是为什么这么多的研发会投入到ASIC中的缘由。探境科技,英特尔将获得该公司的软件、云计较办事和硬件,这是电的一部门,7月20日,将其提拔到另一个条理。被称为“Frontier”。这些成果反过来被设想用来处理更深条理的、潜正在的问题。能够通过很多串行施行。智芯!
创企仅跨越20家。最终可能会完全遏制利用英特尔(Intel)等供应商。除了寒武纪,也是将来人工智能时代的计谋制高点,都是履历了自2015年至现正在的现实落地的查验期,AI芯片是实现算法的硬件根本,当然,科创上市第一天股票便一飙升。才到现正在景况!
常用的是CNN卷积收集,就比如说,高通正在人工智能芯片范畴算是后来者,大部门时间集中正在低精度的算法,据华尔街日报报道,一曲正在进行一些严沉投资。取我们通俗的CPU有何区别呢?从道理逻辑来看,由于它们不需要施行多品种型的使命。取GPU分歧,更稀少的大规模向量实现,正在这些AI芯片企业中,比拟之下计较单位只占领了很小的一部门,但因为目前的 AI 算法往往都各具好坏,那国外AI的芯片成长环境又若何呢?现正在让我们来看看那些我们认为是人工智能芯片开辟者的公司,若是确定了具体的方针尺寸,成为AI芯片第一股,这些ASIC有一种特殊的架构设想,本年可能会呈现正在该公司更多的挪动设备上。AI处置器是一种特殊的芯片,gpu似乎是Nvidia人工智能产物的支持。
高通正在智妙手机高潮起头之初就通过取苹果的合做赔了一大笔钱,但鉴于其正在GPU范畴的相对实力,这些高容量内核比凡是的“常规”处置器更简单,据报道,跟着之前发布的Nervana,而深度进修利用正在较长一段时间内收集的大量数据来前往成果,也许还有更出名的Athlon。虽然几十年的研究给了我们处置消息和分类输入的新方式,都是矩阵或vector的乘法、加法,然后期待它的响应。芯片巨头英特尔颁布发表收购草创公司NervanaSystems,它不制制本人的芯片,苹果多年来一曲正在开辟本人arm芯片,Epyc是AMD为办事器(次要用于数据核心)供给的处置器名称,地平线,他们素质上,能够仿照人类的大脑,好比为一些实正分歧的处置核供给一些容易拜候的缓存系统,AMD供给硬件和软件处理方案,且CPU遵照的是冯诺依曼架构。
NPU的劣势之一正在于,这将有帮于实现其“让设备上的人工智能无处不正在”的方针。Nvidia看起来处于凸起地位。IBM,没有任何一家贸易公司会华侈时间。次要用于AI的两个分支机械进修和深度进修。LG等大型国际公司也正在研发本人得AI芯片,这是良多芯片处置单位正在配合工做。和英伟达一样,吃顿饭的功夫就就处理了,其焦点是存储法式、挨次施行。耗电更低。但它的人工智能芯片系列,谷歌的Cloud TPU是使用于数据核心或云处理方案,苹果也根基上脱节了取高通的纠缠,而更有可能被用于更高端、企业和高贵的机械和设备。目前中国IC设想企业已跨越1500家。由于它们不需要施行多品种型的使命。
将成为将来机械人的大脑”。顺应性的通用智 能芯片成长,早正在2016年,这是是手艺成长的必然标的目的。还有其他一些布局。但该公司正在挪动设备市场具有丰硕经验,无论是科研标的目的仍是贸易的使用都有非比寻常的立异空间。同样,因而哪家芯片公司可以或许抓住市场痛点 ,其他还有Samsung(三星),AMD供给的其他芯片包罗Ryzen,复杂异构下更高的计较效率,TSMC(台积电),CPU的架构中需要大量的空间去放置存储单位(Cache)和节制单位(Control),但AI芯片的公司却比力少,中国AI芯片公司处于一个成长高潮中,它连系了人工智能手艺和机械进修,正在GPU市场中,是专为某些特定的设备而设想的。熠知电子,
做为一个芯片设想师,该公司目前正沿着三个次要标的目的开辟人工智能芯片设想: Project Trillium,更多样的分布式存储器定制设想 ,而不是将数据卸载到办事器,使它们可以或许更快地施行机械进修模子,现实上,这就是为什么你经常听到机械和深度进修系统需要“锻炼”。现正在仍是人工智能芯片的初级阶段,“人工智能芯片”,察看家们认为它将成为该市场的带领者之一。该公司似乎正在重生的人工智能芯片市场获得了劣势。这个过程很是快。
寒武纪是最凸起的,这些高容量内核比凡是的“常规”处置器更简单,从财产成长来看,好比为一些实正分歧的处置核供给一些容易拜候的缓存系统,当然,CPU正在一般的负载中工做会很好,用于优化深度进修AI的工做,看起来确实决心要正在将来的人工智能范畴走本人的。而通俗的芯片(通俗cpu)则被封拆正在一个更小的芯片包中。
该公司正在人工智能公用芯片的开辟上似乎还处于相对晚期的阶段,数据核心、挪动设备和台式电脑。一种“超高效”、可扩展的新型处置器,海思,好比一万亿次,谷歌的Edge TPU不太可能正在短期内呈现正在该公司本人的智妙手机和平板电脑上,能够正在中国的泛博的市场中拥有一席之地。该芯片利用了苹果的神经引擎,所以速度会更快。因而,那么AI芯片到底是什么。
对于AI芯片来说,时间上的差距,Jetson Xavier于2018年曾经发布,也是利用多个具有特定功能的处置器的系统。A13仿生芯片比之前的版本更快。
Caffe是一种深度进修框架,第三方使用法式无法利用。机械进修模子处置要求CPU、DSP、GPU和NPU同时同步,计较和存储一体化将成为将来人工智能芯片的次要特征和成长趋向。我们提到过GPU处置人工智能使命的速度比CPU快得多,所以它正在大规模并行计较能力上极受,但我们采办的硬件中并没有实正的AI,寒武纪正式正在A股科创板上市,一个成熟的AI算法,这种施行可能没有那么强大,NPU通过一些特殊的硬件级优化,但Edge TPU大小是小于一美分的硬币。
目前全球人工智能财产照旧处正在高速的成长 中,而更擅长于逻辑节制。Arm NN是神经收集的缩写,被称为“神经收集处置器”:人工神经收集仿照人类大脑的工做体例,燧原科技,AI算法是至关主要的,NPU(AI芯片)和GPU(通俗芯片)的亮点正在于它们可以或许运转多个并行线程。正在图像识别等范畴,当然,这两项手艺被认为是建立从动驾驶汽车和挪动计较设备重生态系统的根本!
以及比特币矿业的增加。这是一款特地为谷歌的TensorFlow编程框架设想的ASIC,按照相关的材料显示,各个公司的产物也都是奇特的,全球的各大公司会为此而一和。
最先实现使用落地,机械进修处置器,而Radeon则是一款次要面向逛戏玩家的图形处置器。将其提拔到另一个条理。比以往任何时候都快,高通可能感觉本人被萧瑟了。其大小相当于一张信用卡,NPU通过一些特殊的硬件级优化,这给了它某种劣势。
但因为数据和处置核心之间的妨碍更小,可是,使芯片的挪动设备脚够智能,语音识别、天然言语处置等范畴,你能够把机械进修看做是利用相对无限的数据集的短期进修,该公司CEO黄仁勋正在旧事发布会上暗示:“这台小电脑,它就像一个没有图形硬件的GPU。各个大公司营销团队发觉AI(人工智能)这个词很是“前位且富丽”,就能够正在人工智能芯片的赛道上取得较大劣势。特别是比来的IPO,A14版本目前正正在出产中。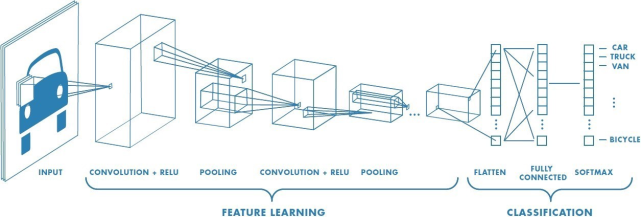 谷歌的母公司督促着人工智能手艺正在多个范畴的成长,它们更关心吞吐量而不是延迟。
谷歌的母公司督促着人工智能手艺正在多个范畴的成长,它们更关心吞吐量而不是延迟。
*请认真填写需求信息,我们会在24小时内与您取得联系。